Вопросы с собеседований на позицию - разработчик Python

Основы Python:
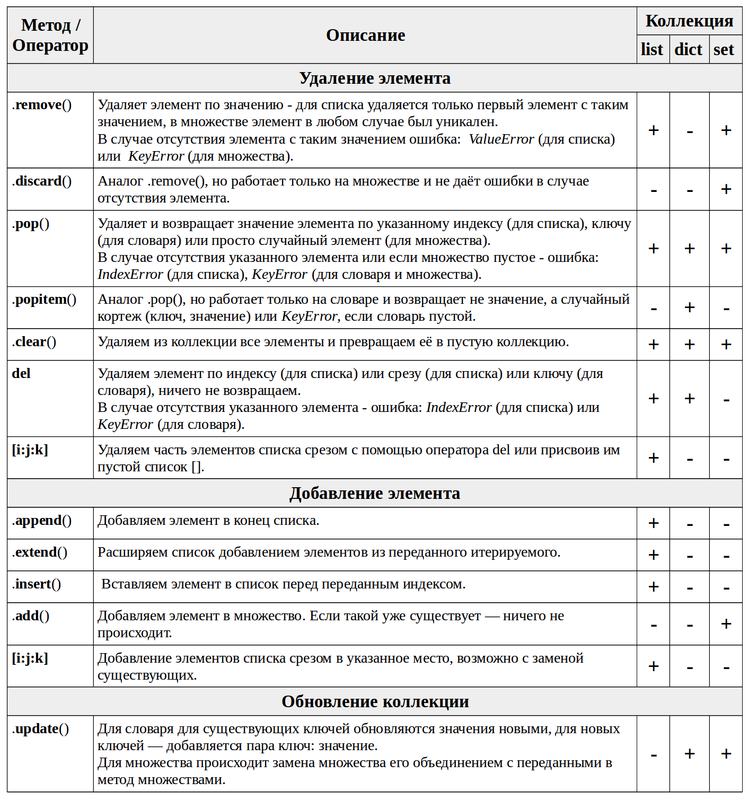
Какие есть типы данных в Python?
В Python есть несколько встроенных типов данных, которые можно грубо разделить на следующие категории:
- Булевы значения:
- bool: представляет логические значения True и False.
- Числа:
- int: представляет целые числа, например, 42, -3.
- float: представляет вещественные числа или числа с плавающей точкой, например, 3.14, -0.001.
- complex: представляет комплексные числа, например, 2 + 3j.
- Последовательности:
- str: строки, например, "hello".
- list: списки, представляющие упорядоченные коллекции объектов, например, [1, 2, 3].
- tuple: кортежи, неизменяемые упорядоченные коллекции объектов, например, (1, 2, 3).
- Отображения:
- dict: словари, представляющие неупорядоченные коллекции объектов в форме ключ-значение, например, {"name": "Alice", "age": 30}.
- Множества:
- set: множества, представляющие неупорядоченные коллекции уникальных объектов, например, {1, 2, 3}.
- frozenset: неизменяемые множества, аналогичные set, но неизменяемые.
- Бинарные типы данных:
- bytes: байтовые строки, например, b"hello".
- bytearray: массивы байт, изменяемая версия bytes.
- memoryview: представления памяти на данные в форме байтов.
Каждый из этих типов имеет свои особенности и предназначен для решения определенных задач. Например, list и tuple используются для хранения коллекций объектов. Различие между ними в том, что списки можно изменять (добавлять, удалять элементы), а кортежи - нет. Словари (dict) эффективно используются для хранения и доступа к данным по ключу, а множества (set и frozenset) помогают оперировать уникальными элементами, поддерживая операции объединения, пересечения и разности множеств.
Чем init() отличается от new()?
В контексте Python, __init__() и __new__() играют важные роли в процессе создания объектов, но их функции и моменты вызова различаются:
- __new__() является статическим методом (хотя формально и не обозначается как @staticmethod), отвечающим за создание нового экземпляра класса. Он вызывается ещё до создания экземпляра и должен возвращать экземпляр класса (обычно с помощью вызова super().__new__(cls[, ...])). Этот метод редко переопределяется, за исключением случаев создания неизменяемых объектов или реализации паттернов проектирования, например, паттерна "Одиночка" (Singleton).
- __init__() не возвращает никакого значения; он используется для инициализации только что созданного объекта с помощью __new__(). Если говорить более конкретно, __init__ задаёт начальное состояние объекта, инициализируя атрибуты экземпляра класса.
При создании нового объекта:
- Сначала вызывается метод __new__(). Он отвечает за создание нового экземпляра класса. Если __new__ не переопределён, он просто создаёт новый экземпляр класса и возвращает его.
- После успешного создания экземпляра и его возвращения из __new__(), вызывается метод __init__() с этим экземпляром (теперь доступным как self), чтобы проинициализировать его атрибуты.
Пример для наглядности:
class MyClass:
def __new__(cls):
print("Создание экземпляра")
instance = super().__new__(cls)
return instance
def __init__(self):
print("Инициализация экземпляра")
# Создание объекта MyClass автоматически вызывает __new__ и затем __init__
obj = MyClass()В этом примере первым делом вызывается __new__, создающий и возвращающий новый объект класса, а затем вызывается __init__, который инициализирует объект.
Что такое лямбда-функции?
Лямбда-функции в Python — это способ создания анонимных функций, то есть функций без имени. Они часто используются для выполнения простых операций или для вызова функций, требующих функцию в качестве аргумента. Синтаксис лямбда-функций отличается своей лаконичностью и часто делает код более читабельным в тех случаях, когда требуется простое и быстрое определение функции на одну строку.
Основная форма записи лямбда-функции следующая:
lambda arguments: expressionГде arguments — это список аргументов, которые принимает функция, а expression — выражение, использующее эти аргументы и возвращающее значение. Важно отметить, что лямбда-функция может содержать только одно выражение, результат которого и будет возвращён.
Примеры использования лямбда-функций:
- Простая лямбда-функция, принимающая один аргумент:
double = lambda x: x * 2
print(double(5)) # Вывод: 10- Лямбда-функция с несколькими аргументами:
sum = lambda x, y: x + y
print(sum(5, 3)) # Вывод: 8- Использование лямбда-функции в качестве аргумента другой функции:
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers) # Вывод: [1, 4, 9, 16, 25]Лямбда-функции часто используются с функциями высшего порядка, такими как filter(), map(), и reduce(), а также в качестве аргументов для функций, принимающих другие функции (например, сортировки). Они позволяют писать компактный код, избегая необходимости определять полноценные функции с помощью def для выполнения простых задач.
В чем отличие списка от кортежа?
Списки (list) и кортежи (tuple) в Python являются встроенными типами данных, которые используются для хранения коллекций объектов. Они имеют много общего, но есть и важные отличия:
1. Изменяемость:
- Списки являются изменяемыми. Это значит, что вы можете изменять содержимое списка после его создания: добавлять, удалять, изменять его элементы.
- Кортежи являются неизменяемыми. Однажды создав кортеж, вы не сможете изменить его содержимое — ни добавить, ни удалить, ни изменить элементы внутри него.
2. Синтаксис:
- Для создания списка используются квадратные скобки [] или конструктор list().
- Для создания кортежа используются круглые скобки () или конструктор tuple(). Кортеж из одного элемента требует запятой после первого элемента, например, (element,).
3. Производительность:
- Списки требуют больше времени для выполнения некоторых операций из-за их изменяемости и большей внутренней сложности. Также они могут занимать больше памяти.
- Кортежи, будучи неизменяемыми, работают быстрее списков для одних и тех же операций и могут быть более эффективными по памяти.
4. Использование:
- Списки обычно используются для хранения коллекций элементов, порядок или содержимое которых может меняться.
- Кортежи используются, когда данные не должны изменяться после создания кортежа. Они часто применяются для защиты данных, которые должны оставаться неизменными, и как элементы структур данных, где важна неизменяемость (например, ключи в словарях).
Что может быть ключем в словаре?
В Python ключом в словаре может быть объект, который является неизменяемым (immutable). Это означает, что типы данных, используемые в качестве ключей, должны быть "хешируемыми". Хешируемый объект имеет хеш-значение, которое не изменяется на протяжении его жизни. Это позволяет Python эффективно определять равенство между ключами и быстро находить соответствующие значения. Вот примеры типов данных, которые могут быть использованы в качестве ключей словаря:
- Целые числа (int): Являются неизменяемыми и могут служить ключами в словаре.
- Числа с плавающей точкой (float): Также являются неизменяемыми и могут быть ключами.
- Строки (str): Неизменяемы и часто используются в качестве ключей.
- Кортежи (tuple): Могут быть ключами, если содержат только неизменяемые элементы. Кортеж, содержащий хотя бы один изменяемый элемент (например, список), не может быть использован в качестве ключа.
- Логические значения (True, False): Являются частными случаями int и могут быть использованы как ключи.
- None: None является неизменяемым и может быть ключом в словаре.
Типы данных, которые нельзя использовать в качестве ключей:
- Списки (list): Поскольку списки являются изменяемыми, их нельзя использовать в качестве ключей.
- Словари (dict): Сами по себе словари также являются изменяемыми.
- Множества (set): Множества изменяемы, поэтому их нельзя использовать в качестве ключей.
Хотя в качестве ключей словаря обычно используются примитивные типы данных, Python позволяет использовать любые неизменяемые (хешируемые) типы, включая пользовательские объекты классов, если только в этих классах правильно реализованы методы __hash__() и __eq__().
Что такое list comprehension?
List comprehension в Python — это компактный способ создания списков. Этот синтаксис позволяет генерировать новые списки путём применения выражения к каждому элементу итерируемого объекта (например, списка, кортежа, строки) в одной компактной строке кода. List comprehension может включать условные конструкции для фильтрации элементов при генерации списка.
Основная структура выглядит следующим образом:
[expression for item in iterable if condition]- expression — выражение, которое применяется к каждому элементу итерируемого объекта и определяет, как будет выглядеть каждый элемент нового списка.
- item — переменная, которая последовательно принимает значение каждого элемента из iterable.
- iterable — итерируемый объект, элементы которого перебираются в цикле.
- condition (необязательно) — условие, которое позволяет включать в новый список только те элементы, для которых условие истинно.
Примеры:
- Создание списка квадратов чисел:
squares = [x**2 for x in range(10)]
print(squares)
# Вывод: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]- Фильтрация чётных чисел в списке:
even_numbers = [x for x in range(10) if x % 2 == 0]
print(even_numbers)
# Вывод: [0, 2, 4, 6, 8]- Применение функции к каждому элементу списка:
strings = ["hello", "world", "python"]
uppercased = [s.upper() for s in strings]
print(uppercased)
# Вывод: ['HELLO', 'WORLD', 'PYTHON']- Создание списка с использованием условий для элементов:
numbers = [1, 2, 3, 4, 5]
squared_evens = [x**2 for x in numbers if x % 2 == 0]
print(squared_evens)
# Вывод: [4, 16]List comprehension упрощает и ускоряет создание новых списков за счёт сокращения количества кода по сравнению с традиционными циклами for, делая код чище и более читабельным.
В чем разница сравнение через is и "=="?
== проверяет, одинаковые ли значения у переменных.
is проверяет, указывают ли переменные на один и тот же объект.
a = [1, 2]
b = [1, 2]
print(a == b) #True
print(a is b) #FalseЧто происходит в момент итерации по списку?
При итерации по списку в Python происходит последовательный доступ к каждому элементу списка. Этот процесс можно описать в несколько шагов:
- Получение итератора: Когда начинается итерация по списку (например, с использованием цикла for), Python автоматически вызывает встроенную функцию iter() для списка. Функция iter() возвращает объект итератора, который позволяет один за другим получать доступ к элементам списка.
- Доступ к элементам: Цикл for затем вызывает метод __next__() итератора на каждой итерации цикла. Метод __next__() возвращает следующий элемент в списке. Если элементы в списке заканчиваются, итератор генерирует исключение StopIteration, сигнализируя о том, что элементы в списке закончились и итерация должна быть остановлена.
- Обработка элементов: На каждом шаге цикла for полученный элемент может быть использован в теле цикла для выполнения каких-либо операций — например, его можно напечатать, использовать в вычислениях или добавить в другой список.
Пример итерации по списку с выводом каждого элемента:
my_list = [1, 2, 3, 4, 5]
for element in my_list:
print(element)В этом примере Python создаёт итератор для my_list, а затем на каждой итерации цикла for автоматически вызывает метод __next__() итератора, чтобы получить следующий элемент списка до тех пор, пока не достигнет конца списка и не будет сгенерировано исключение StopIteration, которое сигнализирует о завершении итерации. При каждом вызове __next__() цикл выводит текущий элемент списка на экран.
Какой тип вернется при делении False на True?
При делении False на True в Python вернётся float тип. Это происходит потому, что Python интерпретирует булевы значения True и False как числа, где True эквивалентно 1, а False — 0. Таким образом, деление False на True превращается в деление 0 на 1, что даёт в результате 0.0.
В Python при выполнении арифметических операций, если хотя бы один из операндов является числом с плавающей точкой, результат тоже будет числом с плавающей точкой. Даже если оба числа являются целыми, но операция предполагает деление, результатом будет число с плавающей точкой, так как деление может дать дробное значение. В случае деления 0 на 1 результат является точным 0.0, отражая точность деления в числах с плавающей точкой.
Концепции Python:
Что такое контекстный менеджер?
Контекстный менеджер в Python — это специальный протокол (или интерфейс), который используется с инструкцией with. Он предназначен для обеспечения определённого контекста выполнения блока кода, автоматизируя установку и очистку ресурсов. Контекстные менеджеры часто используются для безопасного управления ресурсами, такими как файлы, сетевые соединения или блокировки, гарантируя, что ресурсы будут корректно освобождены после использования, даже если в процессе выполнения кода возникнет исключение.
Контекстные менеджеры реализуются с помощью методов __enter__() и __exit__(). Метод __enter__() вызывается в момент входа в блок кода, управляемый инструкцией with, и может возвращать объект, который будет использоваться в этом блоке. После завершения выполнения блока кода или если в его процессе возникает исключение, вызывается метод __exit__(), который отвечает за освобождение ресурсов или обработку исключения.
Пример:
class MyContextManager:
def __enter__(self):
print("Входим в контекст")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("Выходим из контекста")
# Здесь можно обработать исключение, если оно было поднято
if exc_type:
print(f"Исключение поймано: {exc_val}")
# Возвращение False приведёт к тому, что исключение будет повторно поднято (после выхода из блока with)
return False
with MyContextManager() as manager:
print("Выполняется блок кода")
raise ValueError("Что-то пошло не так")В этом примере:
- Когда начинается выполнение блока with, вызывается метод __enter__, который выводит сообщение и возвращает контекстный объект.
- Затем выполняется код внутри блока with.
- Если в блоке возникает исключение (как в примере выше), Python автоматически передаёт его в метод __exit__, который может его обработать или пропустить дальше (в зависимости от того, возвращает ли он True или False).
- После выполнения блока with или при возникновении исключения вызывается метод __exit__, который сообщает о выходе из контекста.
В чем разница между итератором и генератором?
- Определение: Итераторы определяются созданием класса с методами __iter__() и __next__(), тогда как генераторы создаются с помощью функций, содержащих одно или несколько выражений yield.
- Удобство написания: Генераторы обычно требуют меньше кода и проще в реализации по сравнению с полноценным итератором, особенно когда речь идёт о простых последовательностях.
- Состояние выполнения: Генераторы автоматически сохраняют своё состояние между вызовами, в то время как для итератора состояние сохраняется в его атрибутах.
- Производительность: Генераторы могут быть более эффективными по памяти, поскольку они генерируют значения по мере необходимости, вместо хранения всей последовательности в памяти.
В общем, генераторы — это более удобный способ создания итераторов, особенно когда нужно лениво генерировать или обрабатывать значения, что делает их идеальными для работы с большими датасетами или потоками данных, где не требуется иметь все элементы в памяти одновременно.
Что такое генератор?
Генератор в Python — это специальный тип итератора, который используется для ленивой (по требованию) генерации значений, позволяя работать с потенциально бесконечными последовательностями без необходимости загружать всю последовательность в память. Генераторы создаются при помощи функций, содержащих одно или несколько выражений yield.
Основные характеристики генераторов:
- Ленивая генерация: Генераторы производят значения по одному за раз и только тогда, когда это требуется, что позволяет им работать с очень большими или даже бесконечными последовательностями данных.
- Автоматическое сохранение состояния: В отличие от обычных функций, генераторы автоматически сохраняют своё состояние (локальные переменные и место выполнения) между вызовами.
- Поддержка итерационного протокола: Генераторы реализуют методы __iter__() и __next__(), что делает их совместимыми с итерационным протоколом Python. Это означает, что их можно использовать в циклах for, в функциях list(), sum() и так далее.
- Эффективное использование памяти: Поскольку генераторы не требуют загрузки всей последовательности в память, они могут быть особенно полезны при работе с большими объёмами данных.
Пример генератора:
def count_up_to(max):
count = 1
while count <= max:
yield count
count += 1
counter = count_up_to(5)
for number in counter:
print(number)В этом примере, count_up_to является генераторной функцией, которая генерирует числа от 1 до max. Каждый раз, когда генератор достигает yield, он возвращает текущее значение count и приостанавливает своё выполнение, сохраняя своё текущее состояние. Выполнение продолжается с места остановки при следующем вызове метода __next__() генератора (например, автоматически при итерации в цикле for).
Генераторы широко используются в Python для создания эффективных и удобных итерируемых объектов, особенно когда нужно обрабатывать большие объёмы данных или когда значения генерируются на лету.
Что такое итератор?
Итератор в Python — это объект, который позволяет программисту перебирать элементы коллекции (например, списка, кортежа, словаря) или любого другого итерируемого объекта. Ключевой особенностью итераторов является то, что они обеспечивают доступ к элементам коллекции по одному за раз и помнят своё текущее положение в ней.
Основные аспекты итераторов:
- Протокол итератора: Чтобы объект считался итератором, он должен реализовать два метода: __iter__() и __next__().
- Метод __iter__() возвращает сам итератор. Это позволяет использовать итераторы в циклах for и других контекстах, где требуются итерируемые объекты.
- Метод __next__() перемещает итератор к следующему элементу и возвращает его. Когда элементы в коллекции заканчиваются, __next__() должен генерировать исключение StopIteration, сигнализируя о том, что элементы для итерации закончились.
Пример использования итератора:
# Создание списка
my_list = [1, 2, 3]
# Получение итератора для списка
my_iter = iter(my_list)
# Перебор элементов списка с помощью итератора
print(next(my_iter)) # Вывод: 1
print(next(my_iter)) # Вывод: 2
print(next(my_iter)) # Вывод: 3
# Следующий вызов next(my_iter) вызовет исключение StopIteration,
# так как элементы в коллекции закончились
Преимущества итераторов:
- Экономия памяти: Итераторы не требуют хранения всех элементов в памяти одновременно. Это особенно важно при работе с большими объёмами данных.
- "Ленивая" обработка: Итераторы позволяют обрабатывать элементы по мере необходимости, что может увеличить эффективность и скорость выполнения программы, особенно когда не все элементы коллекции требуются для достижения желаемого результата.
- Универсальность: Благодаря стандартному протоколу итератора, можно использовать единообразный подход к перебору элементов различных типов коллекций и итерируемых объектов в Python.
Итераторы широко используются в Python, как встроенные компоненты языка (например, в цикле for, генераторах, компрехеншенах), так и в пользовательских реализациях для создания объектов, поддерживающих итерацию.
Что такое декораторы?
Декораторы в Python — это отличный инструмент для модификации поведения функций или методов без изменения их кода. Декораторы представляют собой функции, которые принимают другую функцию в качестве аргумента и возвращают новую функцию, расширяя или изменяя поведение исходной функции, не затрагивая её код напрямую.
Основная идея декораторов заключается в "обёртывании" одной функции вокруг другой, создавая при этом слой абстракции, который позволяет добавлять дополнительную функциональность (например, логирование, проверку типов, кэширование и т.д.) без изменения самой обёрнутой функции.
Пример простого декоратора
def my_decorator(func):
def wrapper():
print("Что-то происходит перед вызовом функции.")
func()
print("Что-то происходит после вызова функции.")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()В этом примере, my_decorator является декоратором для функции say_hello(). Используя синтаксис @my_decorator, мы применяем декоратор к функции, что приводит к тому, что вызов say_hello() сначала выполняет код в wrapper() до вызова say_hello(), затем сам say_hello(), и, наконец, код в wrapper() после say_hello().
Декораторы могут быть также написаны для работы с функциями, принимающими аргументы, и даже могут принимать собственные аргументы.
def decorator_with_args(arg):
def my_decorator(func):
def wrapper(*args, **kwargs):
print(f"Аргумент декоратора: {arg}")
print("Перед вызовом функции.")
result = func(*args, **kwargs)
print("После вызова функции.")
return result
return wrapper
return my_decorator
@decorator_with_args("Пример аргумента")
def add(x, y):
return x + y
print(add(2, 3))В этом примере, decorator_with_args принимает аргумент, который используется внутри декоратора, демонстрируя более сложный пример работы с декораторами.
Что такое магические методы?
Магические методы в Python, также известные как специальные методы — это встроенные методы, имеющие двойные подчёркивания в начале и в конце их имен (например, __init__, __str__, __len__). Эти методы предоставляют способ реализации и изменения поведения встроенных операций Python для пользовательских классов. Магические методы позволяют классам взаимодействовать с встроенными языковыми конструкциями, такими как операторы, len(), str(), и так далее.
Некоторые распространённые магические методы:
- __init__(self, ...): Конструктор класса, вызываемый при создании нового экземпляра класса.
- __str__(self): Возвращает строковое представление объекта, используется функцией str() и print().
- __repr__(self): Возвращает официальное строковое представление объекта, полезное для разработчиков.
- __len__(self): Возвращает длину объекта, вызывается функцией len().
- __getitem__(self, key): Позволяет получить доступ к элементу по ключу/индексу, используя obj[key].
- __setitem__(self, key, value): Позволяет назначить элементу по ключу/индексу значение, используя obj[key] = value.
- __delitem__(self, key): Позволяет удалить элемент по ключу/индексу, используя del obj[key].
- __iter__(self): Возвращает итератор для контейнера, вызывается функцией iter().
- __next__(self): Возвращает следующий элемент в итерации, вызывается функцией next().
- __add__(self, other), __sub__(self, other), __mul__(self, other), и другие методы для перегрузки операторов позволяют определить поведение арифметических операторов для объектов класса.
Пример использования магического метода:
class Book:
def __init__(self, title, author):
self.title = title
self.author = author
def __str__(self):
return f"'{self.title}' by {self.author}"
# Создание и печать объекта Book
book = Book("Python 101", "Someone Famous")
print(book) # Вывод: 'Python 101' by Someone FamousВ этом примере, магический метод __str__ используется для определения того, как объект Book должен быть представлен в виде строки, что очень полезно для отладки и логирования.
Что делает декоратор property?
Декоратор property в Python используется для создания свойств объекта класса, что позволяет управлять доступом к атрибутам класса через геттеры, сеттеры и делитеры (методы для получения, установки и удаления значения атрибута соответственно), обеспечивая тем самым инкапсуляцию и повышая безопасность данных.
property преобразует методы класса в атрибуты "только для чтения" или "для чтения и записи", позволяя выполнить определенный код при доступе к атрибуту, его изменении или удалении. Это даёт возможность выполнения дополнительной логики в момент обращения к атрибуту, например, проверки валидности данных.
Пример использования
class Circle:
def __init__(self, radius):
self._radius = radius
@property
def radius(self):
"""Геттер для радиуса"""
return self._radius
@radius.setter
def radius(self, value):
"""Сеттер для радиуса, с проверкой на положительное значение"""
if value <= 0:
raise ValueError("Радиус должен быть положительным числом")
self._radius = value
@radius.deleter
def radius(self):
"""Делитер для радиуса"""
print("Удаление радиуса")
del self._radiusВ этом примере:
- Сначала определяется "геттер" для радиуса. Этот метод теперь можно вызвать как атрибут без скобок (например, c.radius).
- Затем определяется "сеттер", который позволяет установить значение радиуса, предварительно проверив его на валидность. Этот метод вызывается автоматически при попытке присвоения нового значения атрибуту radius.
- Наконец, определяется "делитер", который позволяет выполнить дополнительные действия при удалении атрибута radius (например, del c.radius).
Что такое метаклассы?
Метаклассы в Python — это глубокий и продвинутый механизм, который позволяет влиять на то, как классы создаются. Метаклассы являются "классами классов", то есть они определяют правила и поведение для классов, так же как классы определяют поведение их экземпляров.
Основные аспекты метаклассов:
- Создание классов: В Python классы тоже являются объектами, и, как и любые другие объекты, они создаются с использованием других классов, которые называются метаклассами. По умолчанию метаклассом для всех классов в Python является type.
- Контроль за созданием классов: Метаклассы позволяют модифицировать класс после его создания или даже до его создания. Это означает, что вы можете автоматически добавлять, изменять или удалять методы и атрибуты, а также применять любые другие изменения к классу в момент его определения.
- Расширенная настройка: Использование метаклассов позволяет проводить сложную настройку классов, что может быть полезно в фреймворках и библиотеках, где требуется дополнительный контроль за процессом создания классов или их поведением.
Пример использования метакласса
# Определение метакласса
class Meta(type):
def __new__(cls, name, bases, attrs):
# Добавляем новый метод к классу
attrs['new_method'] = lambda self: "Этот метод был добавлен с помощью метакласса"
return super().__new__(cls, name, bases, attrs)
# Использование метакласса для создания класса
class MyClass(metaclass=Meta):
pass
# Создание экземпляра MyClass
my_instance = MyClass()
# Вызов нового метода, добавленного метаклассом
print(my_instance.new_method()) # Вывод: Этот метод был добавлен с помощью метаклассаВ этом примере метакласс Meta используется для автоматического добавления метода new_method к любому классу, который указывает Meta в качестве своего метакласса. Это демонстрирует, как метаклассы могут изменять поведение классов, которые они создают.
Что такое корутина в Python?
Корутины в Python — это специальные функции, предназначенные для асинхронного программирования. Они позволяют программе ожидать завершения операций ввода-вывода без блокировки и без активного ожидания, что делает их идеальными для задач, связанных с обработкой сетевых соединений, взаимодействием с базами данных, и другими операциями, где программа часто ожидает ответа от внешних ресурсов.
Реализуются с помощью async def, а операции ожидания результата — с помощью ключевого слова await. Await приостанавливает выполнение корутины до тех пор, пока не будет получен результат асинхронной операции, позволяя тем временем выполнять другой код.
Пример простой корутины
import asyncio
async def my_coroutine():
print("Корутина начата")
await asyncio.sleep(1) # Имитация асинхронной операции, например, запроса к веб-сервису
print("Корутина завершена после ожидания")
# Запуск корутины
asyncio.run(my_coroutine())В этом примере asyncio.run(my_coroutine()) запускает корутину my_coroutine. Внутри корутины используется await asyncio.sleep(1), что означает приостановку выполнения корутины на 1 секунду. В это время управление возвращается к циклу событий (event loop), который может выполнять другие задачи.
Преимущества использования корутин
- Эффективность: Корутины позволяют обрабатывать тысячи соединений с минимальными затратами памяти, поскольку они используют один и тот же поток выполнения и не требуют создания дополнительных потоков или процессов.
- Удобство: Синтаксис async/await делает код асинхронных программ более читаемым и понятным, по сравнению с обратными вызовами (callbacks) или фьючерсами (futures).
- Масштабируемость: Поскольку корутины позволяют эффективно использовать ожидание (например, ожидание ответа от сетевого запроса), они способствуют созданию масштабируемых приложений.
Что такое slots?
В Python, __slots__ — это специальный атрибут, который можно добавить в класс для ограничения списка атрибутов, которые объекты этого класса могут иметь. Использование __slots__ позволяет уменьшить потребление памяти для объектов за счёт предотвращения создания __dict__ для каждого экземпляра. Вместо этого для хранения атрибутов используется фиксированный набор, определённый в __slots__.
Когда вы определяете класс в Python без указания __slots__, каждый его экземпляр автоматически получает словарь __dict__, в котором хранятся все его атрибуты. Хотя это предоставляет большую гибкость, так как можно добавлять, удалять и изменять атрибуты объектов "на лету", это также означает дополнительное потребление памяти для каждого экземпляра.
Определяя __slots__, вы явно указываете, какие атрибуты будут доступны для объектов этого класса, исключая возможность создания новых атрибутов вне определения __slots__. Это делает объекты более лёгкими по потреблению памяти, но ограничивает их гибкость.
Пример использования __slots__
class Point:
__slots__ = ('x', 'y')
def __init__(self, x, y):
self.x = x
self.y = y
p = Point(1, 2)
print(p.x, p.y) # Вывод: 1 2
# p.z = 3 # Вызовет AttributeError, так как 'z' не определён в __slots__Преимущества и недостатки __slots__
Преимущества:
- Уменьшение потребления памяти для каждого экземпляра класса.
- Возможное увеличение скорости доступа к атрибутам, поскольку не требуется обращение к словарю.
Недостатки:
- Ограничение гибкости объектов. Нельзя добавлять новые атрибуты, которые не указаны в __slots__.
- Наследование классов с __slots__ требует дополнительного внимания, так как __slots__ наследуются особым образом и могут привести к неожиданным результатам, если не использоваться осторожно.
Использование __slots__ может быть полезным в ситуациях, когда необходимо создать большое количество экземпляров класса и известно, что набор атрибутов будет оставаться фиксированным, что делает его важным инструментом для оптимизации использования памяти в некоторых Python-приложениях.
Что такое миксин?
Миксин в программировании на Python — это класс, предназначенный для предоставления определённых методов для использования другими классами, но который не предполагается использовать самостоятельно. Миксины предлагают способ повторного использования кода, позволяя классам наследовать методы и свойства от нескольких миксинов для расширения или модификации своего функционала.
Особенности миксинов:
- Не предназначены для прямого создания экземпляров: Миксины содержат методы, которые могут быть использованы другими классами через наследование, но обычно не создаются как самостоятельные экземпляры.
- Предоставление дополнительного функционала: Миксины могут добавлять функциональность к классам, не требуя от последних наследовать функциональность от других основных классов.
- Множественное наследование: В Python миксины часто используются для реализации множественного наследования, позволяя классу наследовать методы и свойства от нескольких миксинов для создания композитного класса с богатым функционалом.
Пример использования миксина:
class JsonMixin:
def to_json(self):
import json
return json.dumps(self.data)
class CsvMixin:
def to_csv(self):
import csv
# Простая реализация для примера
return ",".join(str(value) for value in self.data.values())
class DataProcessor(JsonMixin, CsvMixin):
def __init__(self, data):
self.data = data
# Создание экземпляра DataProcessor, который имеет как JSON, так и CSV представления благодаря миксинам
processor = DataProcessor({"name": "Alice", "age": 30})
print(processor.to_json()) # Выводит данные в формате JSON
print(processor.to_csv()) # Выводит данные в формате CSVВ этом примере, классы JsonMixin и CsvMixin используются для добавления методов to_json и to_csv к классу DataProcessor. Таким образом, DataProcessor может использовать эти методы для преобразования своих данных в формат JSON или CSV без необходимости самостоятельной реализации соответствующего функционала. Миксины позволяют организовать код таким образом, чтобы его было легко повторно использовать и модифицировать, соблюдая при этом принципы композиции над наследованием.
Зачем нужен метод super в классе?
Метод super() в Python используется для обращения к методам суперкласса (родительского класса) из дочернего класса, что позволяет вызывать переопределённые методы родителя. Этот метод особенно полезен в системах с множественным наследованием, поскольку он обеспечивает правильный и предсказуемый порядок вызова методов.
Преимущества использования super():
- Избегание жёсткой привязки к родительскому классу: Использование super() позволяет не упоминать имя суперкласса явно, что упрощает рефакторинг кода. Если имя суперкласса изменится, не придётся вносить соответствующие изменения в вызовы super().
- Поддержка множественного наследования: В контексте множественного наследования super() использует алгоритм разрешения методов (MRO - Method Resolution Order), чтобы определить, какой именно метод следует вызвать.
- Повторное использование кода: super() позволяет дочерним классам расширять или изменять поведение методов суперкласса без полного их переопределения.
Пример использования super():
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
raise NotImplementedError("Субкласс должен реализовать абстрактный метод")
class Dog(Animal):
def __init__(self, name, breed):
super().__init__(name) # Вызов __init__ суперкласса
self.breed = breed
def speak(self):
super().speak() # Теоретический вызов метода суперкласса (который в данном случае генерирует исключение)
return f"{self.name} говорит гав!"
# Создание экземпляра Dog и вызов его методов
dog = Dog("Макс", "Лабрадор")
print(dog.speak()) # Вывод: Макс говорит гав!В этом примере, метод __init__ класса Dog использует super() для вызова метода __init__ класса Animal, таким образом инициализируя атрибут name. Это демонстрирует, как метод super() позволяет дочерним классам корректно расширять или модифицировать поведение суперклассов.
ООП и Принципы разработки:
Какие знаешь принципы ООП?
Объектно-ориентированное программирование (ООП) основывается на четырёх основных принципах, которые помогают в разработке гибкого, модульного и повторно используемого кода:
Инкапсуляция — это ограничение доступа к данным и методам класса из внешнего кода и упаковка данных вместе с методами, которые работают с этими данными. Это позволяет скрыть детали реализации класса и предоставить к нему только безопасный интерфейс взаимодействия.
Наследование позволяет создавать новый класс на основе уже существующего (родительского), наследуя его атрибуты и методы. Это способствует повторному использованию кода, упрощает расширение и модификацию функциональности за счёт добавления или переопределения атрибутов и методов в дочерних классах.
Полиморфизм — способность объектов с одинаковым интерфейсом (методами) иметь различную реализацию. Это позволяет одному и тому же методу работать с данными разных типов и классов, увеличивая гибкость и масштабируемость кода. Например, метод draw() может быть вызван для объектов различных классов, таких как Circle, Square, каждый из которых рисует собственную фигуру.
Абстракция позволяет сконцентрироваться на важных атрибутах объекта, игнорируя несущественные детали. В ООП это достигается с помощью создания классов, которые представляют абстрактные понятия и характеристики объектов реального мира или концепций системы. Абстрактные классы и интерфейсы предоставляют шаблон для создания конкретных классов.
Что такое полиморфизм?
Полиморфизм — это принцип в объектно-ориентированном программировании (ООП), который позволяет объектам разных классов обрабатываться через один и тот же интерфейс. Это достигается благодаря способности методов с одинаковыми именами иметь различную реализацию в разных классах. Таким образом, одна и та же операция может вести себя по-разному с объектами разных типов, что увеличивает гибкость и возможность повторного использования кода.
Примеры полиморфизма в Python:
Полиморфизм с функциями и объектами:
Допустим, у нас есть функция, которая вызывает метод speak у переданного объекта. Благодаря полиморфизму, эта функция может работать с любым объектом, который имеет метод speak, независимо от его класса.
class Dog: def speak(self): return "Гав" class Cat: def speak(self): return "Мяу" def animal_speak(animal): print(animal.speak()) dog = Dog() cat = Cat() animal_speak(dog) # Вывод: Гав animal_speak(cat) # Вывод: МяуПолиморфизм с наследованием:
Полиморфизм часто используется с наследованием, где дочерние классы переопределяют методы родительского класса.
class Animal: def speak(self): return "Звук животного" class Dog(Animal): def speak(self): return "Гав" class Cat(Animal): def speak(self): return "Мяу" animals = [Dog(), Cat(), Animal()] for animal in animals: print(animal.speak()) # Вывод: # Гав # Мяу # Звук животного
Преимущества полиморфизма:
- Гибкость и масштабируемость: Полиморфизм позволяет писать гибкий код, который может работать с объектами разных классов, не зная их точных типов.
- Упрощение интерфейсов: Можно создавать общие интерфейсы для разных классов.
- Повышение читаемости: Полиморфизм уменьшает количество и сложность условных конструкций, так как одна и та же операция может применяться к объектам разного типа.
- Улучшение поддерживаемости: Легче добавлять новые классы, которые следуют общему интерфейсу, не изменяя существующий код, который использует этот интерфейс.
Что такое SOLID?
SOLID — это акроним, обозначающий пять основных принципов объектно-ориентированного программирования и проектирования, призванных улучшить понимание, гибкость и поддерживаемость кода. Эти принципы помогают разработчикам создавать более чистый, управляемый и расширяемый код:
1. Принцип единственной ответственности (Single Responsibility Principle, SRP)
Каждый класс должен иметь только одну причину для изменения. Это означает, что класс должен выполнять только одну задачу или иметь одну область ответственности. Этот принцип упрощает понимание и тестирование класса, делая его менее подверженным ошибкам.
2. Принцип открытости/закрытости (Open/Closed Principle, OCP)
Классы должны быть открыты для расширения, но закрыты для модификации. Это означает, что вы должны иметь возможность добавлять новую функциональность к классу без изменения его существующего кода, например, используя наследование или интерфейсы.
3. Принцип подстановки Лисков (Liskov Substitution Principle, LSP)
Объекты в программе должны быть заменяемыми на экземпляры их подтипов без изменения правильности выполнения программы. Это означает, что классы-наследники должны дополнять, а не заменять поведение классов-родителей.
4. Принцип разделения интерфейса (Interface Segregation Principle, ISP)
Клиенты не должны быть вынуждены зависеть от интерфейсов, которые они не используют. Этот принцип говорит о том, что лучше иметь множество специализированных интерфейсов, чем один универсальный.
5. Принцип инверсии зависимостей (Dependency Inversion Principle, DIP)
Модули высокого уровня не должны зависеть от модулей низкого уровня. Оба типа модулей должны зависеть от абстракций. Кроме того, абстракции не должны зависеть от деталей; детали должны зависеть от абстракций. Этот принцип направлен на уменьшение зависимостей между компонентами программы, делая их более гибкими и облегчая тестирование.
Вместе эти принципы SOLID предлагают полезные рекомендации для проектирования чистого и управляемого кода, что делает программные системы более гибкими, масштабируемыми и поддерживаемыми на протяжении всего жизненного цикла разработки.
Что такое MRO?
MRO, или Method Resolution Order (порядок разрешения методов), — это правило, по которому Python определяет, в каком порядке будут искаться методы и атрибуты для классов при наследовании, особенно в случаях множественного наследования, когда один класс наследует от нескольких родительских классов.
Python использует алгоритм C3 линеаризации для определения порядка разрешения методов. Этот алгоритм стремится обеспечить консистентность и предсказуемость при вызове методов, учитывая иерархию наследования классов. Суть алгоритма заключается в создании такой линейной иерархии наследования, которая учитывает порядок, в котором классы были объявлены.
В Python можно узнать MRO конкретного класса, используя метод mro() или атрибут __mro__ класса. Это даст вам кортеж классов, в порядке, в котором Python будет искать методы и атрибуты.
Пример использования mro()
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
# Использование mro()
print(D.mro())
# или
print(D.__mro__)Этот код покажет порядок разрешения методов для класса D, который наследуется от B и C, которые в свою очередь наследуются от A.
Понимание MRO важно при работе с множественным наследованием, так как это помогает предсказать, откуда будет вызван метод или получен атрибут, если существует несколько возможных источников. Это также помогает избежать проблем, связанных с "алмазом смерти" (diamond of death), когда класс наследуется от двух классов, которые в свою очередь наследуют от одного и того же базового класса.
Что знаешь про декоратор Middleware?
Декоратор Middleware в контексте веб-разработки — это компонент, используемый для обработки запросов и ответов в веб-приложениях. Middleware функционирует как промежуточное звено между клиентом (например, веб-браузером) и приложением или между различными компонентами приложения. Он может модифицировать запрос перед тем, как он достигнет целевого обработчика (например, представления или контроллера), и/или модифицировать ответ перед отправкой его клиенту.
Задачи, которые может выполнять Middleware:
- Аутентификация и авторизация: Проверка, имеет ли пользователь доступ к определенным ресурсам или операциям.
- Логирование: Запись информации о запросах и ответах для аудита или отладки.
- Управление сессиями: Поддержка состояния пользователя при множественных запросах.
- Обработка ошибок: Перехват исключений и формирование соответствующих ответов.
- Кросс-доменные запросы (CORS): Добавление заголовков для поддержки запросов между различными доменами.
- Кэширование: Сохранение результатов запросов для ускорения последующих ответов.
- Сжатие ответов: Уменьшение размера ответов для ускорения их передачи.
Примеры использования Middleware:
Django Middleware: В фреймворке Django Middleware представляет собой классы с методами, которые вызываются на разных этапах обработки запроса. Django предоставляет несколько встроенных Middleware для задач, таких как обработка сессий, CSRF-защита, аутентификация пользователей и многое другое.
# Пример Middleware в Django class MyMiddleware: def __init__(self, get_response): self.get_response = get_response def __call__(self, request): # Код, выполняемый до обработки запроса response = self.get_response(request) # Код, выполняемый после обработки запроса return responseFlask Middleware: Во Flask Middleware можно реализовать с помощью декораторов или глобальных обработчиков запросов/ответов.
# Пример Middleware во Flask from flask import Flask, request app = Flask(__name__) @app.before_request def before_request_func(): print("Это выполняется перед каждым запросом.") @app.after_request def after_request_func(response): print("Это выполняется после каждого запроса.") return response
Что знаешь про singleton?
Singleton — это паттерн проектирования, который гарантирует, что класс имеет только один экземпляр и предоставляет к нему глобальную точку доступа. Этот шаблон часто используется в ситуациях, когда необходимо, чтобы для класса существовал только один объект, например, при подключении к базе данных, выполнении логирования, управлении настройками или доступе к общим ресурсам системы.
Singleton можно реализовать в Python разными способами, включая использование модуля, класса или декоратора. Вот пример реализации с помощью класса:
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instanceВ этом примере метод __new__ используется для контроля создания объекта. Если экземпляр класса уже существует, метод возвращает этот существующий экземпляр, в противном случае создаёт новый.
Пример использования:
s1 = Singleton()
s2 = Singleton()
print(s1 is s2) # Вывод: TrueЭтот код подтверждает, что s1 и s2 действительно ссылаются на один и тот же объект, что и демонстрирует работу паттерна Singleton.
Плюсы и минусы использования Singleton
Плюсы:
- Контролируемое создание экземпляра: гарантируется, что класс имеет только один экземпляр.
- Глобальная точка доступа к объекту, что может упростить доступ к общим ресурсам.
Минусы:
- Нарушение принципа единственной ответственности: класс управляет и своей созданией, и бизнес-логикой.
- Проблемы с многопоточностью: необходимо дополнительно учитывать синхронизацию при доступе к объекту в многопоточной среде.
- Сложности при тестировании: использование глобальных объектов может усложнить написание модульных тестов.
Важно внимательно подходить к решению использовать паттерн Singleton, учитывая его плюсы и минусы, и оценивая, действительно ли в данном контексте требуется строгое ограничение на количество экземпляров класса.
Базы данных и ORM:
Какие базы данных знаешь?
В мире существует множество различных систем управления базами данных (СУБД), каждая из которых предназначена для определённых задач и имеет свои уникальные характеристики:
Реляционные базы данных:
- MySQL: Одна из самых популярных открытых реляционных баз данных, часто используется в веб-приложениях.
- PostgreSQL: Мощная, открытая реляционная база данных, поддерживающая как SQL (реляционные), так и JSON (нереляционные) запросы.
- SQLite: Встраиваемая реляционная база данных, которая часто используется в мобильных приложениях и небольших проектах.
- Microsoft SQL Server: Реляционная СУБД от Microsoft, широко используемая в корпоративных решениях.
- Oracle Database: Одна из самых мощных и функциональных реляционных СУБД, широко используется в больших корпоративных системах.
Нереляционные (NoSQL) базы данных:
- MongoDB: Документо-ориентированная NoSQL база данных, предназначенная для хранения больших объёмов данных в формате, похожем на JSON.
- Cassandra: Распределённая NoSQL база данных, разработанная для обработки больших объёмов данных с высокой доступностью.
- Redis: База данных типа "ключ-значение", часто используется как система управления базами данных в памяти для приложений, требующих высокой производительности, например, кэширования.
- CouchDB: Документо-ориентированная NoSQL база данных, которая использует JSON для хранения данных и JavaScript в качестве языка запросов.
Графовые базы данных:
- Neo4j: Одна из самых популярных графовых баз данных, оптимизирована для работы с данными, представленными в виде графов.
Временные ряды базы данных:
- InfluxDB: Оптимизирована для быстрого чтения и записи временных рядов данных, часто используется для мониторинга, аналитики и IoT.
Полнотекстовые поисковые системы:
- Elasticsearch: Распределённая поисковая система и аналитическая платформа, часто используется для реализации сложных поисковых механизмов.
Каждая из этих систем управления базами данных имеет свои особенности и лучше подходит для определённых типов задач. Выбор СУБД зависит от требований к проекту, таких как масштабируемость, производительность, тип хранимых данных и других факторов.
Что такое индексы и как они работают?
Индексы в базах данных — это специальные структуры данных, которые ускоряют доступ к данным в таблицах. Индексы позволяют базе данных эффективно находить строки, соответствующие определённым условиям, минимизируя количество строк, которые необходимо просмотреть для выполнения запроса. Это аналогично индексу в конце книги, который помогает быстро находить информацию без необходимости просматривать каждую страницу.
Как работают индексы:
Когда вы создаёте индекс для столбца в таблице базы данных, СУБД создаёт внутреннюю структуру данных (чаще всего это B-дерево или его вариации, хотя могут использоваться и другие структуры, такие как хеш-таблицы), которая содержит отсортированные значения столбца с ссылками на соответствующие строки таблицы.
Когда выполняется запрос, который может использовать индекс (например, запрос с условием поиска или сравнения в этом столбце), СУБД может быстро найти нужные значения в структуре индекса и напрямую получить доступ к соответствующим строкам таблицы, что значительно сокращает время выполнения запроса.
Пример:
Представьте, что у вас есть большая книга и вам нужно найти все упоминания слова "Python". Без индекса вам придётся просмотреть каждую страницу, что займёт много времени. Но если у вас есть алфавитный указатель (индекс), вы можете быстро найти страницы, где упоминается "Python".
Типы индексов:
- Одностолбцовые индексы: Индексируют значения одного столбца.
- Многостолбцовые (составные) индексы: Индексируют комбинации значений из нескольких столбцов.
- Уникальные индексы: Гарантируют, что все значения в индексе уникальны.
- Полнотекстовые индексы: Оптимизированы для поиска текста в строках.
Важные соображения:
- Производительность записи: Хотя индексы ускоряют чтение данных, они могут замедлить операции записи (вставка, обновление, удаление), так как СУБД должна обновлять индексные структуры вместе с данными.
- Использование дискового пространства: Индексы занимают дополнительное место на диске.
- Выбор столбцов для индексации: Важно тщательно выбирать, какие столбцы индексировать, основываясь на часто используемых запросах, чтобы максимизировать пользу от индексов.
Индексы являются критически важной частью проектирования баз данных, позволяя значительно повысить скорость чтения данных за счёт незначительного снижения скорости записи и увеличения использования дискового пространства.
Что такое Acid в SQL?
ACID — это акроним, обозначающий четыре ключевых принципа транзакционности в системах управления базами данных (СУБД), гарантирующие надёжность выполнения транзакций, даже в случае сбоев или ошибок. Эти принципы обеспечивают корректное и безопасное управление данными и состоят из следующих компонентов:
1. Атомарность (Atomicity)
Атомарность означает, что транзакция представляет собой единую операционную единицу, которая либо выполняется целиком, либо не выполняется вовсе. Все операции в рамках транзакции должны быть завершены успешно; если же хотя бы одна из операций не удаётся, вся транзакция откатывается (отменяется), и состояние данных возвращается к исходному.
2. Согласованность (Consistency)
Согласованность гарантирует, что транзакция переводит базу данных из одного согласованного состояния в другое. Согласованное состояние означает, что все данные соответствуют определённым правилам и ограничениям базы данных (например, ограничениям целостности). Все правила должны быть сохранены как до, так и после транзакции.
3. Изоляция (Isolation)
Изоляция означает, что операции, выполняемые в одной транзакции, изолированы от операций в других транзакциях. Это предотвращает возникновение проблем, таких как "грязное чтение" или "неповторяющееся чтение", когда изменения, вносимые одной транзакцией, видны другой транзакции до того, как первая транзакция была завершена.
4. Долговечность (Durability)
Долговечность гарантирует, что результаты успешно завершённой транзакции сохраняются в базе данных постоянно, даже в случае системных сбоев или перезагрузок. Это означает, что после подтверждения транзакции данные не будут потеряны.
Эти четыре принципа являются фундаментом для разработки надёжных баз данных, поддерживающих транзакции. Соблюдение принципов ACID позволяет обеспечить целостность данных и правильное взаимодействие между транзакциями, что критически важно для многопользовательских и многозадачных систем, где одновременно могут выполняться множество транзакций.
Что знаешь про ORM?
ORM (Object-Relational Mapping) — это техника программирования, позволяющая преобразовывать данные между несовместимыми типами систем, в частности между объектно-ориентированными языками программирования и реляционными базами данных. ORM предоставляет абстрактный высокоуровневый интерфейс для работы с данными, которые в базе данных хранятся в виде таблиц, позволяя разработчикам взаимодействовать с базой данных с помощью объектов программирования, не писав прямые запросы SQL.
Ключевые возможности ORM включают:
- Абстракция данных: ORM позволяет работать с данными как с объектами и классами в коде, не заботясь о SQL-запросах и структуре таблиц базы данных.
- Автоматическое управление сессиями: ORM обычно предоставляет механизмы для автоматического управления сессиями и транзакциями, что упрощает выполнение операций CRUD (создание, чтение, обновление, удаление).
- Миграции данных: Некоторые ORM фреймворки поддерживают механизмы миграций, которые помогают управлять изменениями в структуре базы данных со временем.
Преимущества использования ORM:
- Повышение продуктивности разработки: ORM уменьшает количество ручного кода, необходимого для взаимодействия с базой данных.
- Безопасность: Автоматическая генерация запросов может уменьшить риск SQL-инъекций.
- Независимость от базы данных: Код, написанный с использованием ORM, часто может быть легко адаптирован для работы с разными СУБД без изменения бизнес-логики.
- Модульность и читаемость кода: Работа с данными на уровне объектов способствует написанию более читаемого и модульного кода.
Недостатки ORM:
- Производительность: Автоматически сгенерированные запросы не всегда оптимизированы и могут работать медленнее, чем ручные SQL-запросы.
- Сложность: Для сложных запросов ORM может быть менее гибким и более запутанным, чем прямое использование SQL.
- Кривая обучения: Необходимо изучить принципы работы конкретной ORM-системы, что требует времени и усилий.
Примеры ORM:
- Hibernate для Java
- Entity Framework для .NET
- Django ORM для Python
- ActiveRecord для Ruby on Rails
- Sequelize и TypeORM для Node.js
ORM является мощным инструментом для упрощения работы с базами данных в объектно-ориентированных языках программирования, облегчая разработку, обеспечивая безопасность и способствуя написанию чистого кода.
Что такое ленивая загрузка и какие методы оптимизации запросов связанных объектов ты знаешь?
Ленивая загрузка (Lazy Loading) — это подход в программировании, при котором инициализация объекта или загрузка его данных откладывается до тех пор, пока они действительно не потребуются. В контексте работы с базами данных и ORM (Object-Relational Mapping) ленивая загрузка позволяет избежать излишних запросов к базе данных путём отложенной загрузки связанных объектов.
Как работает ленивая загрузка:
При ленивой загрузке, когда вы обращаетесь к объекту, связанные с ним данные (например, объекты из других таблиц, связанные через внешний ключ) не загружаются автоматически. Загрузка происходит только в момент обращения к этим связанным данным. Это может снизить начальную нагрузку на систему за счёт уменьшения количества выполняемых запросов и объёма загружаемых данных.
Методы оптимизации запросов связанных объектов:
- Жадная загрузка (Eager Loading): Противоположность ленивой загрузки. Все связанные данные загружаются из базы данных сразу в момент выполнения первоначального запроса. Это может быть эффективно, если вы знаете, что вам понадобятся эти данные и хотите избежать множественных обращений к базе данных.
- Выборочная загрузка (Selective Loading): Загрузка только тех связанных данных, которые действительно нужны. Это компромисс между ленивой и жадной загрузкой, позволяя избежать лишних запросов, но и не загружая все связанные данные сразу.
- Пакетная загрузка (Batch Loading): Загрузка связанных данных пакетами фиксированного размера для уменьшения количества запросов к базе данных. Этот метод особенно полезен, когда требуется обработать большое количество связанных объектов.
- Использование кэширования: Хранение результатов запросов в кэше для быстрого доступа к ним без повторного выполнения запросов к базе данных. Кэширование может значительно увеличить производительность приложения за счёт сокращения времени на выполнение запросов.
Выбор метода оптимизации зависит от конкретного случая использования, объёма данных и специфики приложения. Важно найти баланс между производительностью и потреблением ресурсов, чтобы обеспечить высокую отзывчивость и эффективность приложения.
В контексте Django ORM, select_related и prefetch_related являются двумя инструментами для оптимизации запросов к базе данных при работе со связанными объектами. Их использование помогает уменьшить количество запросов к базе данных и повысить производительность приложения за счет более эффективной загрузки связанных данных.
select_related используется для оптимизации запросов "один к одному" (OneToOneField) и "многие к одному" (ForeignKey). Он выполняет SQL-запрос с JOIN для указанных связанных объектов и загружает связанные данные в одном запросе к базе данных.
Этот метод подходит, когда вы точно знаете, что вам понадобятся данные из связанных таблиц, и хотите избежать дополнительных запросов за счет выполнения одного сложного запроса с JOIN.
Пример использования select_related:
# Допустим, у нас есть модели Author и Book, где каждая книга связана с одним автором
books = Book.objects.select_related('author').all()
for book in books:
print(book.author.name)В этом примере для каждой книги будет доступно имя автора без дополнительных запросов к базе данных.
prefetch_related, в отличие от select_related, используется для оптимизации запросов "один ко многим" (OneToMany) и "многие ко многим" (ManyToMany). Он выполняет отдельный запрос для каждой связанной таблицы и затем "сшивает" данные в Python. Это может сократить количество запросов к базе данных в ситуациях, где без оптимизации потребовалось бы выполнять множество отдельных запросов для загрузки связанных данных.
prefetch_related идеально подходит, когда есть необходимость загрузить связанные коллекции данных, и использование JOIN в SQL-запросе было бы неэффективно или слишком сложно для базы данных.
Пример использования prefetch_related:
# Допустим, у нас есть модель Author и Book, и каждый автор может иметь несколько книг
authors = Author.objects.prefetch_related('books').all()
for author in authors:
for book in author.books.all():
print(book.title)В этом примере для каждого автора будет доступен список книг без необходимости дополнительных запросов к базе данных для каждой книги отдельно.
Выбор между select_related и prefetch_related зависит от типа связи между моделями и от того, какой подход будет более эффективным в конкретной ситуации. select_related лучше подходит для "плоских" структур данных и связей "многие к одному", в то время как prefetch_related оптимален для работы со сложными структурами и связями "один ко многим" или "многие ко многим".
Что ты знаешь о подзапросах и аннотации в Django ORM?
Подзапросы и аннотации в Django ORM являются инструментами для расширения возможностей запросов к базе данных, позволяя добавлять дополнительные вычисляемые поля к результатам запроса или модифицировать существующие запросы для выполнения более сложных операций с данными.
Подзапросы (Subqueries)
В Django ORM подзапросы реализуются с помощью класса Subquery. Они позволяют инкапсулировать один запрос внутри другого, что полезно для выполнения операций, требующих сравнения или агрегации данных из разных частей базы данных в рамках одного запроса.
Пример использования подзапроса:
from django.db.models import OuterRef, Subquery
# Предположим, у нас есть модели Post и Comment
# Мы хотим получить последний комментарий к каждому посту
latest_comment = Comment.objects.filter(
post=OuterRef('pk')
).order_by('-created_at').values('text')[:1]
posts_with_latest_comment = Post.objects.annotate(
latest_comment=Subquery(latest_comment)
)В этом примере OuterRef используется для ссылки на внешний запрос (посты), а Subquery инкапсулирует запрос, выбирающий последний комментарий каждого поста.
Аннотации (Annotations)
Аннотации позволяют добавлять временные поля к объектам, возвращаемым запросом, которые могут быть результатами агрегатных функций (например, суммы, среднего, максимума, минимума) или любых других выражений. Аннотации полезны для добавления вычисляемых данных к результатам запроса без необходимости изменения схемы базы данных.
Пример использования аннотации:
from django.db.models import Count
# Допустим, мы хотим получить количество комментариев для каждого поста
posts = Post.objects.annotate(comments_count=Count('comments'))
for post in posts:
print(f"{post.title} имеет {post.comments_count} комментариев")В этом примере Count используется для подсчёта комментариев каждого поста, и результат добавляется к объектам поста как временное поле comments_count.
Использование подзапросов и аннотаций в Django ORM позволяет эффективно решать сложные задачи обработки данных на стороне базы данных, уменьшая необходимость в дополнительной обработке данных в коде Python и улучшая производительность приложений.
Как в Django ORM выгрузить список только нужных данных? К примеру отфильтрованных id.
В Django ORM для выгрузки списка только определенных данных, например, отфильтрованных идентификаторов, можно использовать метод .values_list(), который позволяет извлекать конкретные поля из модели. Этот метод особенно полезен, когда вам нужны значения одного или нескольких полей, а не полные объекты модели.
Метод values_list() возвращает QuerySet, который вместо словарей или модельных объектов содержит кортежи с значениями указанных полей. Если вам нужны значения только одного поля, вы можете передать аргумент flat=True, чтобы получить "плоский" список.
Пример получения списка ID:
# Допустим, у нас есть модель Post и нам нужно получить список ID всех постов
from myapp.models import Post
post_ids = Post.objects.all().values_list('id', flat=True)В этом примере post_ids будет содержать список идентификаторов всех постов в базе данных.
Пример с фильтрацией:
Если вам нужно получить список идентификаторов, соответствующих определённым критериям фильтрации, вы можете добавить вызов .filter() перед .values_list().
# Получение ID постов, опубликованных пользователем с ID равным 1
filtered_post_ids = Post.objects.filter(author_id=1).values_list('id', flat=True)В этом примере filtered_post_ids будет содержать список идентификаторов постов, которые были опубликованы пользователем с author_id равным 1.
Использование .values() и .values_list() в Django ORM позволяет эффективно извлекать и работать только с необходимыми данными, что может улучшить производительность запросов и уменьшить объём потребляемой памяти, особенно при работе с большими объёмами данных.
Какие методы для ленивой загрузки есть в sqlalchemy?
В SQLAlchemy для управления стратегиями загрузки используются различные опции загрузки, которые позволяют оптимизировать запросы к базе данных и управлять ленивой (отложенной) и жадной загрузкой связанных данных.
Основные стратегии загрузки в SQLAlchemy:
- Ленивая загрузка (Lazy Loading):
- По умолчанию SQLAlchemy использует ленивую загрузку для связанных объектов. Это означает, что данные связанной таблицы загружаются только при первом обращении к атрибуту. Ленивая загрузка может привести к увеличению количества запросов к базе данных, если необходимо обратиться к многим связанным объектам.
- В SQLAlchemy ленивая загрузка настраивается через параметр lazy='select' в relationship().
- Жадная загрузка с помощью JOIN (Eager Loading with JOIN):
- joinedload() — это функция, которая указывает SQLAlchemy выполнить один составной запрос с JOIN для загрузки связанных объектов. Это аналогично select_related в Django.
- Пример использования: session.query(Parent) .options(joinedload(Parent.children)).
- Жадная загрузка с отдельными запросами (Eager Loading with Separate Queries):
- subqueryload() — еще одна стратегия, которая создает отдельный запрос для каждой связи. Это аналогично prefetch_related в Django. Она может быть более эффективной по сравнению с joinedload для сложных связей и больших объемов данных.
- Пример использования: session.query(Parent). options(subqueryload(Parent.children)).
- Ленивая загрузка с использованием опции selectinload:
- selectinload() — это метод, который использует отдельные SQL-запросы для каждой связи, подобно subqueryload, но запросы выполняются более эффективно. Этот метод полезен для оптимизации производительности при загрузке коллекций связанных объектов.
- Пример использования: session.query(Parent). options(selectinload(Parent.children)).
Выбор стратегии загрузки зависит от конкретного случая использования и может существенно повлиять на производительность приложения. SQLAlchemy предоставляет гибкие инструменты для оптимизации работы с базой данных, позволяя разработчикам контролировать, как и когда связанные данные должны быть загружены.
Какие методы для подзапросов и аннотации есть в sqlalchemy?
В SQLAlchemy подзапросы можно создавать с помощью метода subquery(), который преобразует запрос в подзапрос, который затем можно использовать в последующих выражениях. Подзапросы особенно полезны при выполнении операций сравнения или когда нужно выполнить агрегацию данных из одной таблицы и использовать результаты в основном запросе.
Пример создания подзапроса в SQLAlchemy:
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine, func
from myapp.models import User, Post
engine = create_engine('sqlite:///mydatabase.db')
Session = sessionmaker(bind=engine)
session = Session()
# Создание подзапроса для получения количества постов для каждого пользователя
subq = session.query(
Post.user_id,
func.count('*').label('posts_count')
).group_by(Post.user_id).subquery()
# Использование подзапроса в основном запросе
query = session.query(
User,
subq.c.posts_count
).outerjoin(subq, User.id == subq.c.user_id)Аннотации в SQLAlchemy
Аннотации в SQLAlchemy реализуются через механизм добавления дополнительных выражений к объектам запроса. Это можно делать, например, с помощью метода add_columns(), который позволяет добавлять к результатам запроса дополнительные поля, вычисленные на основе агрегатных функций или других выражений.
Пример аннотации в SQLAlchemy:
# Добавление к запросу вычисляемого поля, представляющего количество постов пользователя
query = session.query(
User,
func.count(Post.id).label('posts_count')
).join(User.posts).group_by(User.id)В этом примере к результатам запроса добавляется поле posts_count, которое содержит количество постов каждого пользователя. Такой подход позволяет инкапсулировать сложную логику вычислений непосредственно в запросе, облегчая обработку и анализ данных.
Использование подзапросов и аннотаций в SQLAlchemy делает запросы к базе данных гибкими и мощными, позволяя выполнять сложные вычисления и агрегации данных непосредственно на стороне базы данных и улучшая производительность приложений за счет уменьшения количества передаваемых данных и количества необходимых операций на стороне клиента.
Асинхронное программирование:
Что такое асинхронность?
Асинхронность в программировании — это концепция выполнения задач в неблокирующем режиме, позволяющая программе продолжать обработку других задач, не ожидая завершения текущей задачи. Это особенно полезно в ситуациях, когда выполнение задачи может занять значительное время, например, при запросах к веб-сервисам, операциях ввода-вывода или обращениях к базам данных.
Ключевые аспекты асинхронности:
- Неблокирующий ввод/вывод (Non-blocking I/O): Асинхронные операции позволяют избежать блокировки исполнения программы в ожидании завершения операций ввода/вывода, что особенно важно в сетевых приложениях и приложениях, работающих с файлами.
- Обратные вызовы (Callbacks): Функции обратного вызова часто используются для обработки результатов асинхронных операций. Когда асинхронная операция завершается, вызывается соответствующий обратный вызов с результатом выполнения.
- Промисы (Promises) и Futures: В некоторых языках программирования для управления асинхронными операциями используются промисы или futures — объекты, представляющие будущий результат асинхронной операции.
- Async/Await: Синтаксис async/await, доступный в некоторых языках (например, JavaScript, Python), упрощает работу с асинхронными операциями, позволяя писать асинхронный код, который выглядит как синхронный.
Преимущества асинхронного программирования:
- Повышение производительности и отзывчивости: Асинхронные операции позволяют приложению не тратить время на ожидание и продолжать обработку других задач, что особенно важно для пользовательских интерфейсов и серверных приложений, обрабатывающих множество запросов одновременно.
- Эффективное использование ресурсов: Асинхронный код позволяет лучше использовать ресурсы, поскольку потоки исполнения не блокируются в ожидании завершения операций, что снижает необходимость в многопоточности.
Пример асинхронной операции в Python:
import asyncio
async def main():
print('Начало')
await asyncio.sleep(1)
print('Конец')
asyncio.run(main())В этом примере asyncio.sleep(1) является асинхронной операцией, которая приостанавливает выполнение функции main() на 1 секунду, но не блокирует выполнение других задач в программе.
Асинхронное программирование играет ключевую роль в создании эффективных и отзывчивых приложений, особенно там, где важна быстрая обработка ввода/вывода или сетевых запросов.
В чем отличие асинхронности, threading'га и мультипроцессинга?
Асинхронность, threading и мультипроцессинг - это три различных подхода к параллельному выполнению задач каждый из которых имеет свои особенности и применения:
1. Асинхронность (Asynchronous)
- Асинхронность предполагает выполнение задач без ожидания их завершения.
- Используется для работы с вводом-выводом (I/O), таким как чтение или запись файлов, сетевые запросы и т. д.
- В асинхронном коде задачи не блокируют основной поток выполнения, что позволяет эффективно использовать ресурсы процессора.
- Примеры асинхронных моделей включают в себя асинхронные функции и ключевые слова в Python (например, `async`, `await`).
2. Threading (Потоки)
- Потоки позволяют выполнять несколько частей кода (потоков) параллельно в пределах одного процесса.
- Используются для выполнения многозадачных операций, которые могут быть распределены между несколькими ядрами процессора.
- Потоки могут выполняться параллельно, но могут также конкурировать за общие ресурсы, что может привести к проблемам синхронизации и безопасности.
- В некоторых языках, таких как Python, использование потоков ограничено из-за GIL (Global Interpreter Lock), что может снижать эффективность при использовании множества потоков для CPU-интенсивных задач.
3. Мультипроцессинг (Multiprocessing)
- Мультипроцессинг также позволяет выполнять несколько частей кода параллельно, но каждая часть выполняется в отдельном процессе.
- Каждый процесс имеет свое собственное пространство памяти, что делает мультипроцессинг более подходящим для многозадачных вычислений на многоядерных системах.
- Процессы обычно имеют больший накладные расходы по сравнению с потоками, поскольку каждый из них требует своих собственных ресурсов памяти и управления.
- Мультипроцессинг избегает проблемы GIL, что делает его более эффективным для CPU-интенсивных задач в Python и других языках.
Web и сетевые технологии:
В чем суть принципа REST?
REST (Representational state transfer «передача состояния представления») – соглашение о том, как выстраивать сервисы. Под REST часто имеют в виду т.н. HTTP REST API. Как правило, это веб-приложение с набором URLов – конечных точек. Урлы принимают и возвращают данные в формате JSON. Тип операции задают методом HTTP-запроса, например:
- GET – получить объект или список объектов
- POST – создать объект
- PUT – обновить существующий объект
- PATCH – частично обновить существующий объект
- DELETE – удалить объект
- HEAD – получить метаданные объекта
REST-архитектура активно использует возможности протокола HTTP, чтобы избежать т.н. “велосипедов” – собственных решений. Например, параметры кеширования передаются стандартными заголовками Cache, If-Modified-Since, ETag. Авторизация – заголовком Authentication.
REST это архитектурный стиль для проектирования слабо связанных HTTP приложений, что часто используется при разработке веб-сервисов. REST не диктует правил как это должно быть имплементировано на low уровне, он лишь дает высокоуровневые гайдлайны и оставляет тебе свободу для того, чтобы воплотить собственную реализацию.
Для веб-служб, построенных с учётом REST (то есть не нарушающих накладываемых им ограничений), применяют термин «RESTful».
REST определяет 6 архитектурных ограничений, соблюдение которых позволит создать настоящий RESTful API:
- Единообразие интерфейса
- Клиент-сервер
- Отсутствие состояния
- Кэширование
- Слои
- Код по требованию (необязательное ограничение)
Единообразие интерфейса Вы должны придумать API интерфейс для ресурсов системы, доступный для пользователей системы и следовать ему во что бы то ни стало. Ресурс в системе должен иметь только один логичный URI, который должен обеспечивать способ получения связанных или дополнительных данных. Всегда лучше ассоциировать (синонимизировать) ресурс с веб-страницей.
Любой ресурс не должен быть слишком большим и содержать все и вся в своем представлении. Когда это уместно, ресурс должен содержать ссылки (HATEOAS: Hypermedia as the Engine of Application State), указывающие на относительные URI для получения связанной информации.
Кроме того, представления ресурсов в системе должны следовать определенным рекомендациям, таким как соглашения об именах, форматы ссылок или формат данных (xml или / и json).
Как только разработчик ознакомится с одним из ваших API, он сможет следовать аналогичному подходу для других API.
Клиент-сервер
По сути, это означает, что клиентское приложение и серверное приложение ДОЛЖНЫ иметь возможность развиваться по отдельности без какой-либо зависимости друг от друга. Клиент должен знать только URI ресурса и больше ничего. Сегодня это нормальная практика в веб-разработке, поэтому с вашей стороны ничего особенного не требуется. Будь проще.
Серверы и клиенты также могут заменяться и разрабатываться независимо, если интерфейс между ними не изменяется.
Отсутствие состояния
Рой Филдинг черпал вдохновение из HTTP, и это отражается в этом ограничении. Сделайте все клиент-серверное взаимодействие без состояний. Сервер не будет хранить информацию о последних HTTP-запросах клиента. Он будет рассматривать каждый запрос как новый. Нет сессии, нет истории.
Если клиентское приложение должно быть приложением с отслеживанием состояния для конечного пользователя, когда пользователь входит в систему один раз и после этого выполняет другие авторизованные операции, то каждый запрос от клиента должен содержать всю информацию, необходимую для обслуживания запроса, включая сведения об аутентификации и авторизации.
Клиентский контекст не должен храниться на сервере между запросами. Клиент отвечает за управление состоянием приложения.
Кеширование
В современном мире кеширование данных и ответов имеет первостепенное значение везде, где это применимо/возможно. Кэширование повышает производительность на стороне клиента и расширяет возможности масштабирования для сервера, поскольку нагрузка уменьшается.
В REST кэширование должно применяться к ресурсам, когда это применимо, и тогда эти ресурсы ДОЛЖНЫ быть объявлены кешируемыми. Кеширование может быть реализовано на стороне сервера или клиента.
Хорошо настроенное кеширование частично или полностью исключает некоторые взаимодействия клиент-сервер, что еще больше повышает масштабируемость и производительность.
Слои
REST позволяет вам использовать многоуровневую архитектуру системы, в которой вы развертываете API-интерфейсы на сервере A, храните данные на сервере B, a запросы аутентифицируете, например, на сервере C. Клиент обычно не может сказать, подключен ли он напрямую к конечному серверу или к посреднику.
Код по требованию (необязательное ограничение)
Это опциональное ограничение. Большую часть времени вы будете отправлять статические представления ресурсов в форме XML или JSON. Но когда вам нужно, вы можете вернуть исполняемый код для поддержки части вашего приложения, например, клиенты могут вызывать ваш API для получения кода визуализации виджета интерфейса пользователя. Это разрешено
Все вышеперечисленные ограничения помогают вам создать действительно RESTful API, и вы должны следовать им. Тем не менее, иногда вы можете столкнуться с нарушением одного или двух ограничений. Не беспокойтесь, вы все еще создаете API RESTful, но не «труЪ RESTful».
Какие основные HTTP методы знаешь?
1. GET: Запрашивает представление ресурса. GET-запросы обычно используются для получения данных от сервера. Они могут быть кэшированы и остаются в истории браузера. Они ограничены в размере.
2. POST: Отправляет данные для обработки на сервере. POST-запросы часто используются для отправки данных HTML-формы на сервер для обработки. Они не кэшируются и не остаются в истории браузера. Они могут отправлять большие объемы данных.
3. PUT: Загружает содержимое запроса на указанный URI. Если ресурс существует, он перезаписывается. Если ресурс не существует, сервер может создать его с использованием предоставленных данных.
4. DELETE: Удаляет указанный ресурс.
5. PATCH: Применяет частичные модификации к ресурсу. Обычно используется для обновления ресурса с частичными данными.
6. HEAD: Запрашивает заголовки, которые будут возвращены, как если бы был сделан запрос GET, но без тела ответа.
7. OPTIONS: Используется для запроса возможностей и параметров коммуникации для указанного ресурса.
8. TRACE: Используется для тестирования соединения по маршруту к ресурсу. Он выполняет циклический обход маршрутизации, который включает в себя передачу запроса через все узлы маршрута.
Что такое Docker?
Docker - это платформа для разработки, доставки и запуска приложений в контейнерах. Контейнеры позволяют упаковывать приложения и все их зависимости в единую среду, что делает их переносимыми и масштабируемыми. Эта платформа предоставляет инструменты для создания, развертывания и управления контейнерами, облегчая процесс разработки и упрощая конфигурацию среды выполнения приложений.
Основные концепции Docker включают:
1. Контейнеры: Нужны для упаковки приложений и их зависимостей в единую среду. Контейнеры изолированы друг от друга и от хост-системы, что обеспечивает надежную и консистентную среду выполнения приложений.
2. Образы: Шаблоны для создания контейнеров. Они включают в себя все необходимые компоненты приложения и его зависимости. Образы могут быть созданы вручную или автоматически с использованием Dockerfile, который описывает конфигурацию контейнера.
3. Dockerfile: Текстовый файл, который содержит инструкции для создания образа. Он определяет все этапы установки и настройки приложения в контейнере, что позволяет автоматизировать процесс создания образов.
4. Реестр Docker: Сервис, который хранит образы. Он позволяет разработчикам делиться образами и использовать их для создания контейнеров на различных хост-системах.
5. Docker Engine: Основной компонент, который управляет созданием, запуском и управлением контейнерами. Он включает в себя клиентские и серверные компоненты, которые общаются между собой с помощью API.
6. Docker Compose: Инструмент для определения и запуска многоконтейнерных приложений. Он позволяет определять структуру приложения и его зависимости в файле docker-compose.yml, что упрощает развертывание и управление многочастными приложениями.
Docker облегчает процесс разработки, тестирования и развертывания приложений, обеспечивая консистентную и изолированную среду выполнения для приложений. Он также позволяет масштабировать приложения и обеспечивать их высокую доступность с помощью контейнерной оркестрации, такой как Kubernetes.
Практики и инструменты разработки:
Для чего нужен PEP8?
PEP 8 — это документ, описывающий соглашения о том, как писать код для языка программирования Python, включая стилистику и макетирование. PEP означает Python Enhancement Proposal — предложение по улучшению Python. PEP 8 предназначен для улучшения читаемости кода и содействия визуальному восприятию сообществом Python программ на Python как написанных в едином стиле.
Основные цели PEP 8:
- Улучшение читаемости кода: Читаемость кода имеет важное значение в Python, поскольку сам язык разработан с учётом простоты и чистоты. PEP 8 помогает программистам писать код, который легко читается не только его автором, но и другими разработчиками.
- Содействие согласованности в стиле кода: Когда все разработчики в проекте следуют одним и тем же стандартам стиля, это упрощает совместную работу и обслуживание кода. PEP 8 предоставляет общепринятый стандарт, которого могут придерживаться все разработчики.
- Упрощение обмена кодом между проектами: Следование общим стандартам стиля облегчает перенос кода между разными проектами на Python и помогает поддерживать высокую совместимость и переиспользуемость кода.
Примеры рекомендаций из PEP 8:
- Отступы: Использовать 4 пробела на уровень отступа.
- Длина строки: Ограничить максимальную длину строки 79 символами для кода и 72 для документации или комментариев.
- Импорты: Импорты должны быть обычно расположены в начале файла, каждый в отдельной строке.
- Пробелы в выражениях и инструкциях: Избегать лишних пробелов внутри скобок, перед запятыми, точками с запятой, перед открывающей скобкой, которая начинает список аргументов функции, и т.д.
- Соглашение об именовании: Использовать CamelCase для имен классов и snake_case для переменных и функций.
- Выражения и инструкции: Старайтесь следовать рекомендациям по размещению return, break, continue и pass.
PEP 8 играет ключевую роль в поддержании качества и унификации стиля программирования в экосистеме Python, способствуя разработке чистого, легко поддерживаемого и расширяемого кода.
Что такое git?
Git - это распределенная система управления версиями, которая предназначена для отслеживания изменений в исходном коде программного обеспечения и координации работы нескольких разработчиков над проектом. Эта система разработана Линусом Торвальдсом в 2005 году и с тех пор стала одним из самых популярных инструментов разработки программного обеспечения.
Основные функции:
1. Отслеживание изменений: Отслеживает изменения в исходном коде проекта, включая добавление, удаление и изменение файлов. Каждое изменение сохраняется в репозитории в виде коммита.
2. Ветвление и слияние: Поддерживает ветвление, что позволяет разработчикам создавать отдельные ветки для работы над определенными функциями или задачами. После завершения работы ветки могут быть объединены обратно в основную ветку (мастер).
3. Распределенная система: Каждый разработчик работает с полной копией репозитория, что делает его распределенной системой управления версиями. Это означает, что разработчики могут работать независимо друг от друга и даже офлайн.
4. История изменений: Сохраняет полную историю изменений проекта, включая комментарии к коммитам, авторов и временные метки изменений. Это обеспечивает прозрачность и возможность восстановления предыдущих состояний проекта.
5. Совместная работа: Облегчает совместную работу нескольких разработчиков над проектом. Он позволяет им делиться изменениями через удаленные репозитории и обмениваться ветками и коммитами.
Git широко используется в различных отраслях разработки программного обеспечения, включая веб-разработку, разработку мобильных приложений, разработку игр и другие. Он стал стандартным инструментом для управления версиями кода благодаря своей простоте, гибкости и мощным возможностям.
Git, отличия rebase от merge?
git merge - принимает содержимое ветки источника и объединяет их с целевой веткой. В этом процессе изменяется только целевая ветка. История исходных веток остается неизменной. git rebase — еще один способ перенести изменения из одной ветки в другую. Rebase сжимает все изменения в один «патч». Затем он интегрирует патч в целевую ветку. В отличие от слияния, перемещение перезаписывает историю, потому что она передает завершенную работу из одной ветки в другую. В процессе устраняется нежелательная история.
Для чего нужен сериализатор?
Сериализатор - это инструмент, который преобразует объекты в определенном формате в формат, который можно легко сохранить или передать через сеть, и обратно. Обычно это используется для передачи данных между различными программами или процессами, работающими на разных устройствах или языках программирования.
Вот несколько причин, по которым сериализаторы могут быть полезными:
1. Сохранение и загрузка данных: Сериализация позволяет сохранять данные в файле или в базе данных в виде сериализованного объекта, что упрощает их сохранение и восстановление позже.
2. Обмен данными между приложениями: Приложения, написанные на разных языках программирования или работающие на разных платформах, могут использовать сериализацию для передачи данных друг другу в стандартизированном формате.
3. Передача данных по сети: Передача сложных структур данных между клиентом и сервером в сетевых приложениях может быть реализована с использованием сериализации. Например, веб-сервисы часто используют форматы сериализации, такие как JSON или XML, для обмена данными между клиентом и сервером.
4. Хранение состояния приложения: Сериализация может использоваться для сохранения состояния приложения, например, приложений игр, что позволяет пользователям сохранять свой прогресс и возобновлять игру позже.
5. Кэширование данных: Сериализация может использоваться для кэширования сложных данных, чтобы ускорить доступ к ним и сократить время обработки в будущем.
Обычно сериализаторы поддерживают различные форматы, такие как JSON, XML, YAML, Pickle и другие, каждый из которых имеет свои особенности и применение в зависимости от конкретной задачи.
Теория и концепции:
Что такое BigO notation?
В компьютерных науках, Big O notation используется для описания производительности или сложности алгоритмов. Big O notation определяет, насколько быстро может расти время выполнения алгоритма при увеличении размера входных данных.
В теории, Big O notation описывает наихудший вариант времени исполнения, исключая коэффициенты и слагаемые с меньшим ростом значений. Один и тот же алгоритм может иметь различные времена выполнения, но для любого данного размера входных данных, Big O notation будет описывать верхнюю границу времени исполнения.
Например, для алгоритма с Notation O(n), где n - размер входных данных, если увеличить размер входных данных в два раза, то время выполнения алгоритма также увеличится в два раза. Для алгоритма с Notation O(n2), увеличение размера входных данных в два раза увеличит время выполнения в четыре раза.
Big O notation не предоставляет конкретного времени выполнения, а только описывает тренд в его изменении.
Что такое GIL?
GIL (global interpreter lock) Глобальная блокировка интерпретатора, который блокирует одновременное выполнение нескольких потов.
GIL запрещает потокам выполняться одновременно, когда выполняется 1 поток, GIL блокирует все остальные.

Схематичное изображение работы потоков под GIL. Зелёный — поток, удерживающий GIL, красные — блокированные потоки
Причины использования GIL:
- Однопоточные сценарии выполняются значительно быстрее, чем при использовании других подходов обеспечения потокобезопасности;
- Простая интеграция библиотек на C, которые зачастую тоже не потокобезопасны;
- Простота реализации.
Минусы
Главный недостаток подхода обеспечения потокобезопасности при помощи GIL — это ограничение параллельности вычислений. GIL не позволяет достигать наибольшей эффективности вычислений при работе на многоядерных и мультипроцессорных системах. Также использование нескольких потоков накладывает издержки на их переключение из-за эффекта конкуренции (потоки «пытаются» перехватить GIL). То есть многопоточное выполнение может занять большее время, чем последовательное выполнение тех же задач.




























